Unsupervised Variant Clustering Identifies Genetic Subtypes of Disease
Unsupervised Variant Clustering Identifies Genetic Subtypes of Disease
Mizikovsky, D.; Wray, N. R.; Shah, S.; Palpant, N.
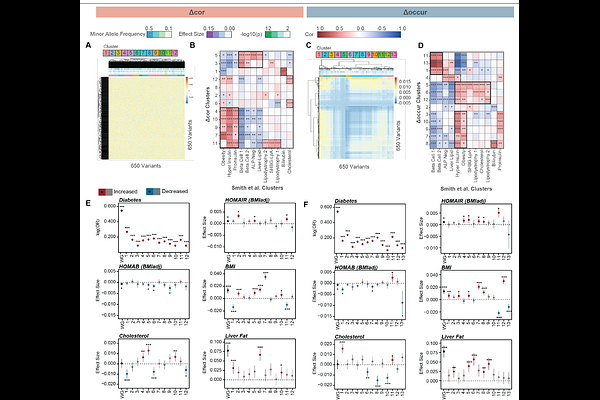
AbstractCurrent approaches to identify disease subtypes rely on prior knowledge or external phenotypic references that limit their generalisability across traits. This study presents an unsupervised, phenotype-free framework that analyses the genetic co-occurrence of variants across individuals to identify variant clusters underpinning disease heterogeneity. The approach is developed and validated using simulated combinations of real phenotypes then applied to dissect disease subtypes of type 2 diabetes and asthma. The approach captures clinically established mechanistic profiles in type 2 diabetes and asthma without requiring any reference phenotype data and enables identification of plasma proteins for novel subtype-specific biomarkers and drug targets. Lastly, we demonstrate that variants with conflicting effects on disease-relevant traits are resolved into distinct clusters, identifying subtypes with opposing phenotypic profiles that are lost by the aggregated genetic risk. Co-occurrence-based clustering provides a scalable strategy for understanding disease heterogeneity across diverse populations by identifying biologically meaningful subtype structure from genotype data alone.