On the Predictive Power of Representation Dispersion in Language Models
On the Predictive Power of Representation Dispersion in Language Models
Yanhong Li, Ming Li, Karen Livescu, Jiawei Zhou
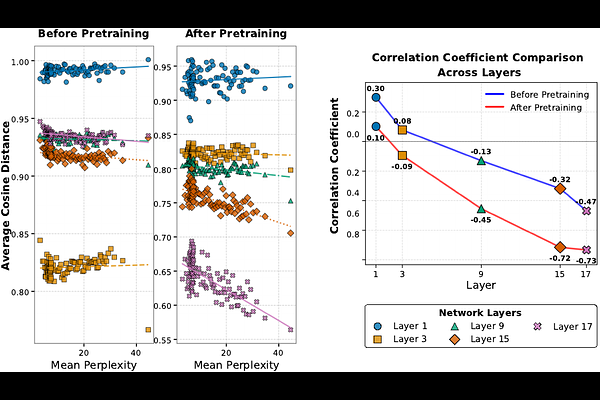
AbstractWe show that a language model's ability to predict text is tightly linked to the breadth of its embedding space: models that spread their contextual representations more widely tend to achieve lower perplexity. Concretely, we find that representation dispersion - the average pairwise cosine distance among hidden vectors - strongly and negatively correlates with perplexity across diverse model families (LLaMA, Qwen, and others) and domains (Wikipedia, news, scientific abstracts). Beyond illustrating this link, we show how dispersion can be leveraged for a range of practical tasks without requiring labeled data. First, measuring dispersion on unlabeled text allows us to predict downstream accuracy in new domains, offering a data-efficient tool for model selection. Next, we find that identifying layers with higher dispersion pinpoints the best representations for retrieval-based methods such as kNN-LM, bypassing exhaustive layer-by-layer searches. Finally, we integrate a simple push-away objective into training, which increases dispersion in both single-domain and cross-domain scenarios and directly improves perplexity in each.