Outside Knowledge Conversational Video (OKCV) Dataset -- Dialoguing over Videos
Outside Knowledge Conversational Video (OKCV) Dataset -- Dialoguing over Videos
Benjamin Reichman, Constantin Patsch, Jack Truxal, Atishay Jain, Larry Heck
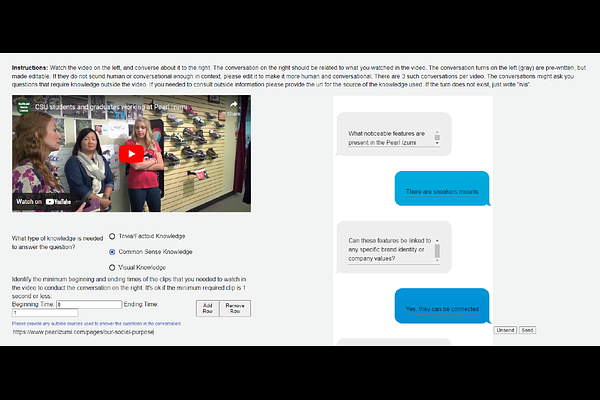
AbstractIn outside knowledge visual question answering (OK-VQA), the model must identify relevant visual information within an image and incorporate external knowledge to accurately respond to a question. Extending this task to a visually grounded dialogue setting based on videos, a conversational model must both recognize pertinent visual details over time and answer questions where the required information is not necessarily present in the visual information. Moreover, the context of the overall conversation must be considered for the subsequent dialogue. To explore this task, we introduce a dataset comprised of $2,017$ videos with $5,986$ human-annotated dialogues consisting of $40,954$ interleaved dialogue turns. While the dialogue context is visually grounded in specific video segments, the questions further require external knowledge that is not visually present. Thus, the model not only has to identify relevant video parts but also leverage external knowledge to converse within the dialogue. We further provide several baselines evaluated on our dataset and show future challenges associated with this task. The dataset is made publicly available here: https://github.com/c-patsch/OKCV.