Debating for Better Reasoning: An Unsupervised Multimodal Approach
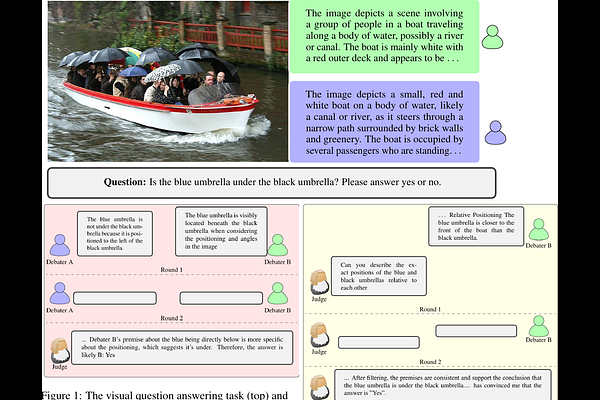
Debating for Better Reasoning: An Unsupervised Multimodal Approach
Ashutosh Adhikari, Mirella Lapata
AbstractAs Large Language Models (LLMs) gain expertise across diverse domains and modalities, scalable oversight becomes increasingly challenging, particularly when their capabilities may surpass human evaluators. Debate has emerged as a promising mechanism for enabling such oversight. In this work, we extend the debate paradigm to a multimodal setting, exploring its potential for weaker models to supervise and enhance the performance of stronger models. We focus on visual question answering (VQA), where two "sighted" expert vision-language models debate an answer, while a "blind" (text-only) judge adjudicates based solely on the quality of the arguments. In our framework, the experts defend only answers aligned with their beliefs, thereby obviating the need for explicit role-playing and concentrating the debate on instances of expert disagreement. Experiments on several multimodal tasks demonstrate that the debate framework consistently outperforms individual expert models. Moreover, judgments from weaker LLMs can help instill reasoning capabilities in vision-language models through finetuning.