Understanding and Improving Length Generalization in Recurrent Models
Understanding and Improving Length Generalization in Recurrent Models
Ricardo Buitrago Ruiz, Albert Gu
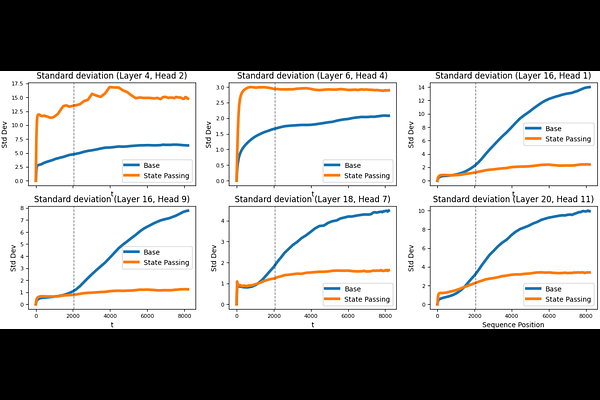
AbstractRecently, recurrent models such as state space models and linear attention have become popular due to their linear complexity in the sequence length. Thanks to their recurrent nature, in principle they can process arbitrarily long sequences, but their performance sometimes drops considerably beyond their training context lengths-i.e. they fail to length generalize. In this work, we provide comprehensive empirical and theoretical analysis to support the unexplored states hypothesis, which posits that models fail to length generalize when during training they are only exposed to a limited subset of the distribution of all attainable states (i.e. states that would be attained if the recurrence was applied to long sequences). Furthermore, we investigate simple training interventions that aim to increase the coverage of the states that the model is trained on, e.g. by initializing the state with Gaussian noise or with the final state of a different input sequence. With only 500 post-training steps ($\sim 0.1\%$ of the pre-training budget), these interventions enable length generalization for sequences that are orders of magnitude longer than the training context (e.g. $2k\longrightarrow 128k$) and show improved performance in long context tasks, thus presenting a simple and efficient way to enable robust length generalization in general recurrent models.