Task-parallelism in SWIFT for heterogeneous compute architectures
Task-parallelism in SWIFT for heterogeneous compute architectures
Abouzied M. A. Nasar, Benedict D. Rogers, Georgios Fourtakas, Scott T. Kay, Matthieu Schaller
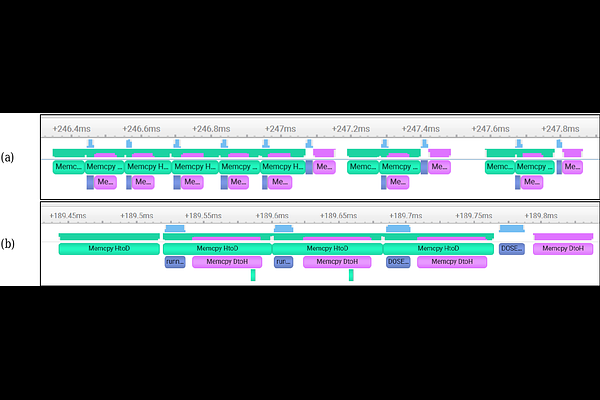
AbstractThis paper highlights the first steps towards enabling graphics processing unit (GPU) acceleration of the smoothed particle hydrodynamics (SPH) solver for cosmology SWIFT and creating a hydrodynamics solver capable of fully leveraging the hardware available on heterogeneous exascale machines composed of central and graphics processing units (CPUs and GPUs). Exploiting the existing task-based parallelism in SWIFT, novel combinations of algorithms are presented which enable SWIFT to function as a truly heterogeneous software leveraging CPUs for memory-bound computations concurrently with GPUs for compute-bound computations in a manner which minimises the effects of CPU-GPU communication latency. These algorithms are validated in extensive testing which shows that the GPU acceleration methodology is capable of delivering up to 3.5x speedups for SWIFTs SPH hydrodynamics computation kernels when including the time required to prepare the computations on the CPU and unpack the results on the CPU. Speedups of 7.5x are demonstrated when not including the CPU data preparation and unpacking times. Whilst these measured speedups are substantial, it is shown that the overall performance of the hydrodynamic solver for a full simulation when accelerated on the GPU of state-of-the-art superchips, is only marginally faster than the code performance when using the Grace Hopper superchips fully parallelised CPU capabilities. This is shown to be mostly due to excessive fine-graining of the tasks prior to offloading on the GPU. Fine-graining introduces significant over-heads associated with task management on the CPU hosting the simulation and also introduces un-necessary duplication of CPU-GPU communications of the same data.