Whom Do We Prefer to Learn From in Observational Reinforcement Learning?
Whom Do We Prefer to Learn From in Observational Reinforcement Learning?
Morishita, G.; Murawski, C.; Yadav, N.; Suzuki, S.
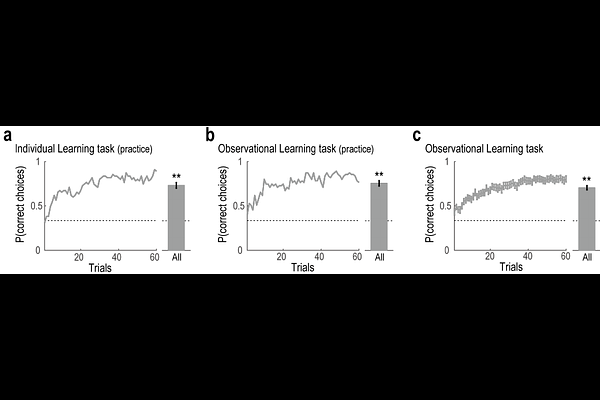
AbstractLearning by observing others experiences is a hallmark of human intelligence. While the neurocomputational mechanisms underlying observational learning are well understood, less is known about whom people prefer to learn from in the context of observational learning. One hypothesis posits that learners prefer individuals who exhibit a high degree of decision noise (randomness in action selection), \'free riding\' on the costly exploration of others. An alternative hypothesis suggests that learners prefer individuals with low decision noise, and imitate consistent and reliable behavior. In a preregistered experiment, we found that most participants preferred to learn from low-noise individuals. Furthermore, exploratory analyses revealed that participants who preferred low-noise individuals tended to rely on imitation of others\' actions, whereas those who preferred high-noise individuals relied more on learning from others\' reward outcomes. These findings offer a potential computational account of how learning styles shape partner selection in social learning.