Pencil Puzzle Bench: A Benchmark for Multi-Step Verifiable Reasoning
Pencil Puzzle Bench: A Benchmark for Multi-Step Verifiable Reasoning
Justin Waugh
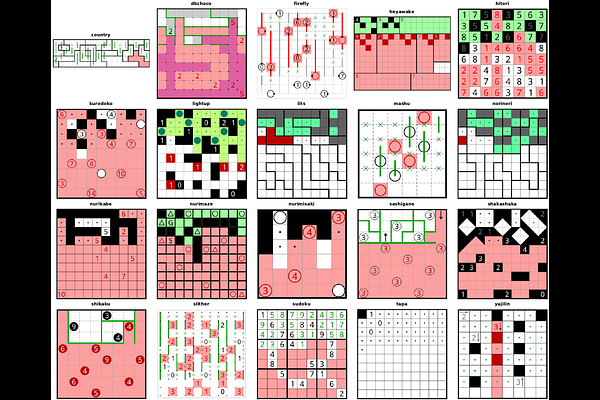
AbstractWe introduce Pencil Puzzle Bench, a framework for evaluating large language model reasoning through pencil puzzles, a family of constraint-satisfaction problems closely related to NP-complete problems, with deterministic, step-level verification. From a database of 62,231 puzzles across 94 varieties with verified unique solutions, we select a benchmark of 300 puzzles spanning 20 varieties and evaluate 51 models from 11 providers in two modes: direct ask (single-shot) and agentic (multi-turn with iterative verification). A key differentiator of our benchmark is that every intermediate board state can be checked against variety-specific constraints, localizing errors to the exact rule violated, providing the infrastructure for dense, per-move reward signals for process supervision and reinforcement learning. Our evaluation reveals two distinct axes of capability: (1) reasoning effort scaling, where GPT-5.2 improves 81x from no reasoning to maximum effort; and (2) agentic iteration, where Claude Opus 4.6 rises from 0.3% to 30.0% through iterative checking, while GPT-5.2@xhigh improves from 20.2% to 56.0%. Agentic attempts span a median of 29 turns over 17 minutes, with the longest exceeding 1,221 turns and 14.3 hours - a demanding test of long-context utilization, not just reasoning.