Beyond Compromise: Pareto-Lenient Consensus for Efficient Multi-Preference LLM Alignment
Beyond Compromise: Pareto-Lenient Consensus for Efficient Multi-Preference LLM Alignment
Renxuan Tan, Rongpeng Li, Zhifeng Zhao, Honggang Zhang
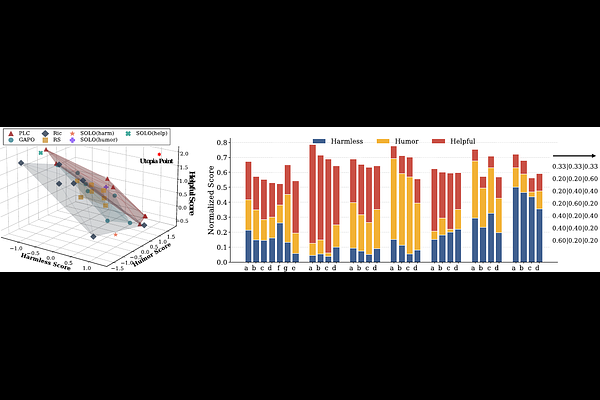
AbstractTranscending the single-preference paradigm, aligning LLMs with diverse human values is pivotal for robust deployment. Contemporary Multi-Objective Preference Alignment (MPA) approaches predominantly rely on static linear scalarization or rigid gradient projection to navigate these trade-offs. However, by enforcing strict conflict avoidance or simultaneous descent, these paradigms often prematurely converge to local stationary points. While mathematically stable, these points represent a conservative compromise where the model sacrifices potential global Pareto improvements to avoid transient local trade-offs. To break this deadlock, we propose Pareto-Lenient Consensus (PLC), a game-theoretic framework that reimagines alignment as a dynamic negotiation process. Unlike rigid approaches, PLC introduces consensus-driven lenient gradient rectification, which dynamically tolerates local degradation provided there is a sufficient dominant coalition surplus, thereby empowering the optimization trajectory to escape local suboptimal equilibrium and explore the distal Pareto-optimal frontier. Theoretical analysis validates PLC can facilitate stalemate escape and asymptotically converge to a Pareto consensus equilibrium. Moreover, extensive experiments show that PLC surpasses baselines in both fixed-preference alignment and global Pareto frontier quality. This work highlights the potential of negotiation-driven alignment as a promising avenue for MPA. Our codes are available at https://anonymous.4open.science/r/aaa-6BB8.