Towards Provably Unbiased LLM Judges via Bias-Bounded Evaluation
Towards Provably Unbiased LLM Judges via Bias-Bounded Evaluation
Benjamin Feuer, Lucas Rosenblatt, Oussama Elachqar
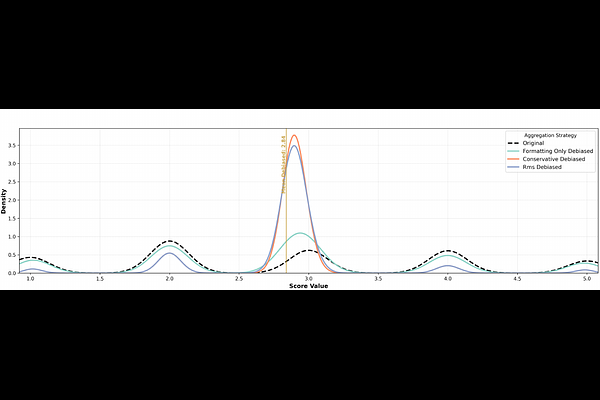
AbstractAs AI models progress beyond simple chatbots into more complex workflows, we draw ever closer to the event horizon beyond which AI systems will be utilized in autonomous, self-maintaining feedback loops. Any autonomous AI system will depend on automated, verifiable rewards and feedback; in settings where ground truth is sparse or non-deterministic, one practical source of such rewards is an LLM-as-a-Judge. Although LLM judges continue to improve, the literature has yet to introduce systems capable of enforcing standards with strong guarantees, particularly when bias vectors are unknown or adversarially discovered. To remedy this issue, we propose average bias-boundedness (A-BB), an algorithmic framework which formally guarantees reductions of harm/impact as a result of any measurable bias in an LLM judge. Evaluating on Arena-Hard-Auto with four LLM judges, we achieve (tau=0.5, delta=0.01) bias-bounded guarantees while retaining 61-99% correlation with original rankings across formatting and schematic bias settings, with most judge-bias combinations exceeding 80%. The code to reproduce our findings is available at https://github.com/penfever/bias-bounded-evaluation.