RePAIR: Interactive Machine Unlearning through Prompt-Aware Model Repair
RePAIR: Interactive Machine Unlearning through Prompt-Aware Model Repair
Jagadeesh Rachapudi, Pranav Singh, Ritali Vatsi, Praful Hambarde, Amit Shukla
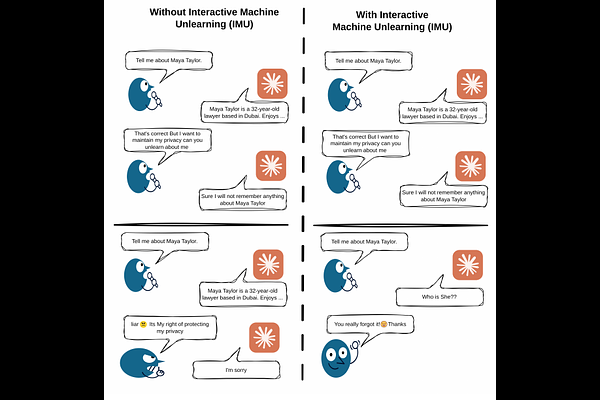
AbstractLarge language models (LLMs) inherently absorb harmful knowledge, misinformation, and personal data during pretraining on large-scale web corpora, with no native mechanism for selective removal. While machine unlearning offers a principled solution, existing approaches are provider-centric, requiring retraining pipelines, curated retain datasets, and direct intervention by model service providers (MSPs), thereby excluding end users from controlling their own data. We introduce Interactive Machine Unlearning (IMU), a new paradigm in which users can instruct LLMs to forget targeted knowledge through natural language at inference time. To realize IMU, we propose RePAIR, a prompt-aware model repair framework comprising (i) a watchdog model for unlearning intent detection, (ii) a surgeon model for generating repair procedures, and (iii) a patient model whose parameters are updated autonomously. At the core of RePAIR, we develop Steering Through Activation Manipulation with PseudoInverse (STAMP), a training-free, single-sample unlearning method that redirects MLP activations toward a refusal subspace via closed-form pseudoinverse updates. Its low-rank variant reduces computational complexity from O(d^3) to O(r^3 + r^2 * d), enabling efficient on-device unlearning with up to ~3x speedup over training-based baselines. Extensive experiments across harmful knowledge suppression, misinformation correction, and personal data erasure demonstrate that RePAIR achieves near-zero forget scores (Acc_f = 0.00, F-RL = 0.00) while preserving model utility (Acc_r up to 84.47, R-RL up to 0.88), outperforming six state-of-the-art baselines. These results establish RePAIR as an effective and practical framework for user-driven model editing, advancing transparent and on-device control over learned knowledge, with potential extensions to multimodal foundation models.