Parcae: Scaling Laws For Stable Looped Language Models
Parcae: Scaling Laws For Stable Looped Language Models
Hayden Prairie, Zachary Novack, Taylor Berg-Kirkpatrick, Daniel Y. Fu
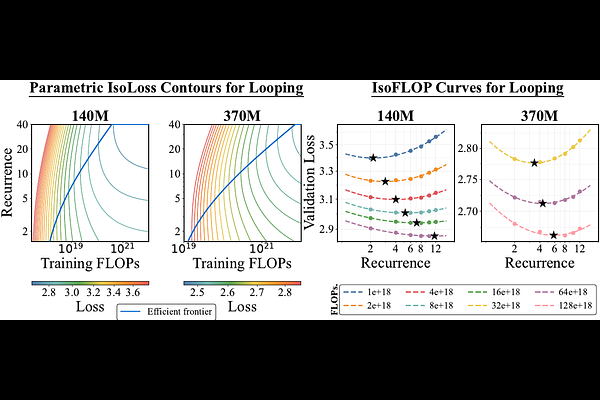
AbstractTraditional fixed-depth architectures scale quality by increasing training FLOPs, typically through increased parameterization, at the expense of a higher memory footprint, or data. A potential alternative is looped architectures, which instead increase FLOPs by sending activations through a block of layers in a loop. While promising, existing recipes for training looped architectures can be unstable, suffering from residual explosion and loss spikes. We address these challenges by recasting looping as a nonlinear time-variant dynamical system over the residual stream. Via a linear approximation to this system, we find that instability occurs in existing looped architectures as a result of large spectral norms in their injection parameters. To address these instability issues, we propose Parcae, a novel stable, looped architecture that constrains the spectral norm of the injection parameters via discretization of a negative diagonal parameterization. As a result, Parcae achieves up to 6.3% lower validation perplexity over prior large-scale looped models. Using our stable looped architecture, we investigate the scaling properties of looping as a medium to improve quality by increasing FLOPs in training and test-time. For training, we derive predictable power laws to scale FLOPs while keeping parameter count fixed. Our initial scaling laws suggest that looping and data should be increased in tandem, given a fixed FLOP budget. At test-time, we find that Parcae can use looping to scale compute, following a predictable, saturating exponential decay. When scaled up to 1.3B parameters, we find that Parcae improves CORE and Core-Extended quality by 2.99 and 1.18 points when compared to strong Transformer baselines under a fixed parameter and data budget, achieving a relative quality of up to 87.5% a Transformer twice the size.