Development of Hybrid Artificial Intelligence Training on Real and Synthetic Data: Benchmark on Two Mixed Training Strategies
Development of Hybrid Artificial Intelligence Training on Real and Synthetic Data: Benchmark on Two Mixed Training Strategies
Paul Wachter, Lukas Niehaus, Julius Schöning
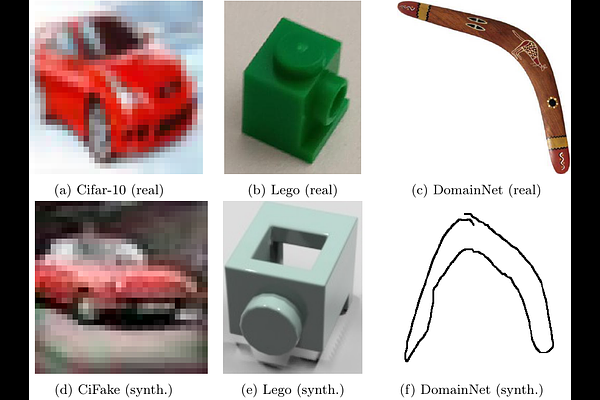
AbstractSynthetic data has emerged as a cost-effective alternative to real data for training artificial neural networks (ANN). However, the disparity between synthetic and real data results in a domain gap. That gap leads to poor performance and generalization of the trained ANN when applied to real-world scenarios. Several strategies have been developed to bridge this gap, which combine synthetic and real data, known as mixed training using hybrid datasets. While these strategies have been shown to mitigate the domain gap, a systematic evaluation of their generalizability and robustness across various tasks and architectures remains underexplored. To address this challenge, our study comprehensively analyzes two widely used mixing strategies on three prevalent architectures and three distinct hybrid datasets. From these datasets, we sample subsets with varying proportions of synthetic to real data to investigate the impact of synthetic and real components. The findings of this paper provide valuable insights into optimizing the use of synthetic data in the training process of any ANN, contributing to enhancing robustness and efficacy.