A graph-based learning approach to predict the effects of gene perturbations on molecular phenotypes
A graph-based learning approach to predict the effects of gene perturbations on molecular phenotypes
Jin, Y.; Sverchkov, Y.; Sushkova, A.; Ohtake, M.; Emfinger, C.; Craven, M.
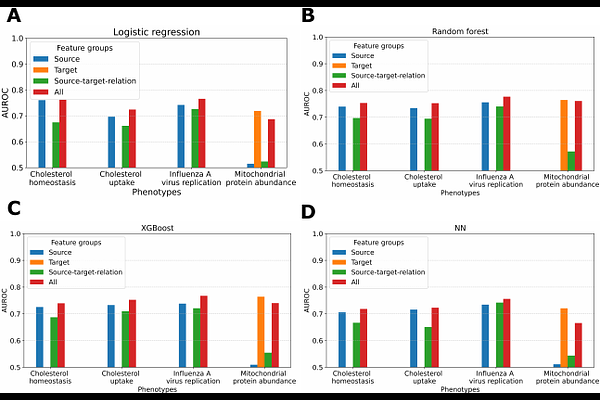
AbstractMotivation: Large-scale gene knockdown/knockout screens have been used to gain insight into a wide array of phenotypes and biological processes. However, conducting such experiments is expensive and labor-intensive. In this work, we present a general graph-based machine-learning approach that can predict the effects of gene perturbations on molecular phenotypes of interest given some measured phenotypic effects of other gene perturbations. The motivation for learning models that can predict the effects of gene perturbations is fourfold. Such models can (1) predict effects for unmeasured genes in cases in which cost or technical barriers preclude perturbing every gene, (2) prioritize unmeasured genes or sets of genes for subsequent perturbation experiments, (3) hypothesize mechanisms that underlie the relationships between the perturbed genes and their effects, and (4) generalize to other unmeasured phenotypes of interest. Results: We evaluate our approach by applying it, in conjunction with four different learning methods, to learn models for four varied phenotypes. Our empirical evaluation demonstrates that the learned models (1) show relatively high levels of predictive accuracy across the four phenotypes, (2) have better predictive accuracy than several standard baselines, (3) can often learn accurate models with small training sets, (4) benefit from having multiple sources of evidence in the input representation, (5) can, in many cases, transfer their predictive value to other phenotypes. Data availablity: The assembled data sets and source code for this work are available at: https://github.com/Craven-Biostat-Lab/graph-molecular-phenotype-prediction