Kaminari: a resource-frugal index for approximate colored k-mer queries
Kaminari: a resource-frugal index for approximate colored k-mer queries
Levallois, V.; Shibuya, Y.; Le Gal, B.; Patro, R.; Peterlongo, P.; Pibiri, G. E.
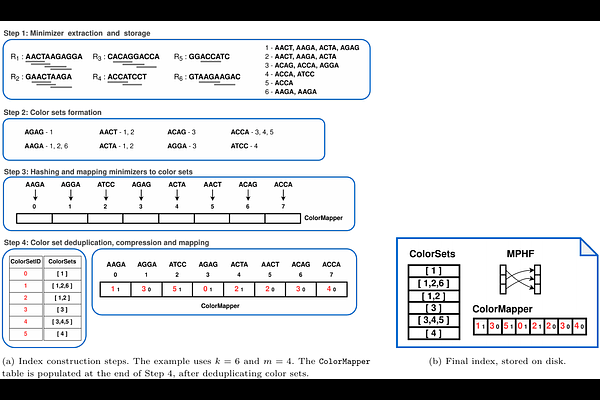
AbstractMotivation: The problem of identifying the set of textual documents from a given database containing a query string has been studied in various fields of computing, e.g., in Information Retrieval, Databases, and Computational Biology. We consider the approximate version of this problem, that is, the result set is allowed to contain some false positive matches (but no false negatives), and focus on the specific case where the indexed documents are DNA strings. In this setting, state-of-the-art solutions rely on Bloom filters as a way to index all k-mers (substrings of length k) in the documents. To answer a query, the k-mers of the query string are tested for membership against the index and documents that contain at least a user-prescribed fraction of them (e.g., 75-80%) are returned. Methods and results: Here, we explore an alternative index design based on k-mer minimizers and integer compression methods. We show that a careful implementation of this design outperforms previous solutions based on Bloom filters by a wide margin: the index has lower memory footprint and faster query times, while false positive matches have only a minor impact on the ranking of the documents reported. This trend is robust across genomic datasets of different complexity and query workloads. Software: The software is implemented in C++17 and available under the MIT license at https://github.com/yhhshb/kaminari. Reproducibility information and additional results are provided at github.com/vicLeva/benchmarks_kaminari.