TB-Bench: A Systematic Benchmark of Machine Learning and Deep Learning Methods for Second-Line TB Drug Resistance Prediction
TB-Bench: A Systematic Benchmark of Machine Learning and Deep Learning Methods for Second-Line TB Drug Resistance Prediction
VP, B.; Jaiswal, S.; Meshram, A.; PVS, D.; S C, S.; Narayanan, M.
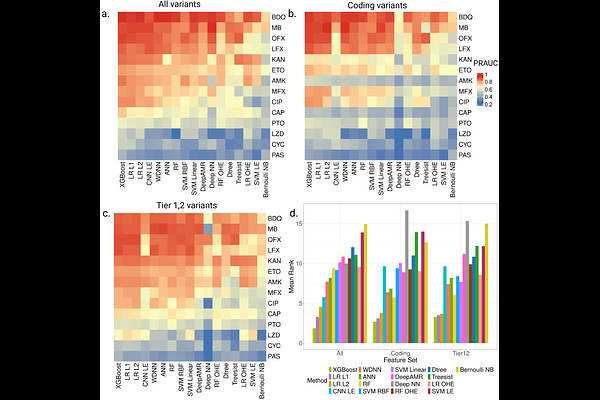
AbstractDrug-resistant tuberculosis (TB), characterized by prolonged treatment regimens and suboptimal treatment outcomes, remains a major obstacle to global TB elimination. Advances in sequencing technologies have enabled the development of machine-learning (ML) approaches, including deep-learning (DL) methods, to predict drug resistance directly from genomic data. However, a significant gap remains in translating these advances into clinical practice. While current approaches reliably predict resistance to first-line drugs, they show consistently lower and more variable performance for second-line drugs compared with traditional drug-susceptibility testing. To characterize these limitations and assess practical utility, we conducted a comprehensive survey and standardized benchmarking of current approaches for predicting TB drug resistance using whole-genome sequencing (WGS) data. Using systematic selection criteria, we identified 20 traditional ML and DL models from 8 studies and evaluated drug-specific versions across 14 second-line drugs within a unified framework. To account for methodological heterogeneity, the models were evaluated using three distinct feature sets reflecting variability in input representations. We trained and evaluated the models on different subsets of the WHO dataset, comprising 50,801 samples, and assessed generalizability using an external validation dataset comprising 1,199 samples. In the internal evaluation on the held-out WHO test dataset, traditional ML models using binary features achieved higher predictive performance than DL models. For example, XGBoost achieved the highest area under the precision-recall curve (PRAUC) scores (46%-93%) for 10 of the 14 drugs. However, performance varied substantially across drugs. Notably, the superior performance of traditional ML models - even with limited feature sets - highlights their applicability in low-resource settings. When evaluated on the external validation dataset, the performance of traditional ML and DL models was comparable, and neither class of models demonstrated substantial improvement over catalogue-based approaches, underscoring challenges in cross-dataset generalization. Overall, this benchmarking study provides a comprehensive and systematic evaluation of current approaches, establishes a rigorous evaluation framework for future comparisons, and identifies key methodological considerations necessary to advance robust drug resistance prediction in clinical settings. To enhance reproducibility and facilitate the application of TB-Bench to additional datasets and models, we have made the source code publicly available at https://github.com/BIRDSgroup/TB-Bench.